Credit Card Defaults Part 1: Classification
Classification with Imbalanced Target
Summary
The goal of this project was to design predictive binary classification models to predict whether credit card account holders will default on their payments in the next month. The models address the imbalance in the target variable. Gradient Boosting and neural network models are highlighted. The paper and presentation walk through the data understanding and preparation, different models tested, methodology, evaluation and anticipated follow-up steps to the project.
Tools
- Scikit-learn
- Keras
- Seaborn
- Matplotlib
- Numpy
- Pandas
- Scipy
Data
Models / Methods / Metrics
- Gradient Boosting Classification
- Artificial Neural Network
- Random Forest
- Logistic Regression / LASSO Logistic Regression
- Receiver Operating Characteristic curve and Youden’s J statistic
- Feature Selection:
- Principal Component Analysis
- ANOVA and Feature Importance Models
- Log-Transformation and Scaling
- GridSearch
- Recall, Log-Loss and Binary Crossentropy Loss
Results
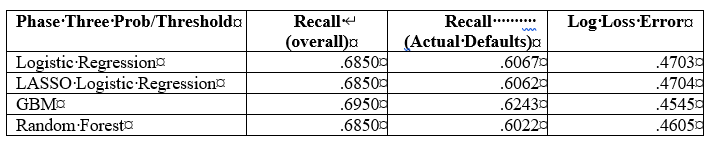
The Gradient Boosting Classification model had the best Recall and Log Loss Error scores. 62.43% of the actual default accounts were labeled as true positives. The Log Loss Error was .4545. The Artificial Neural Network had a Recall score of .6989 and a binary crossentropy loss of .5958. These scores resulted from addressing the imbalanced target variable.
Project Preview
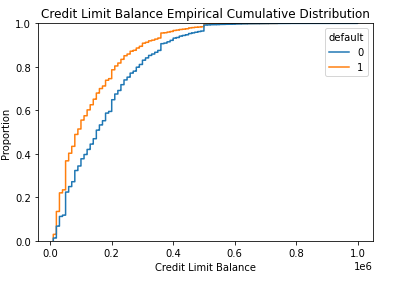
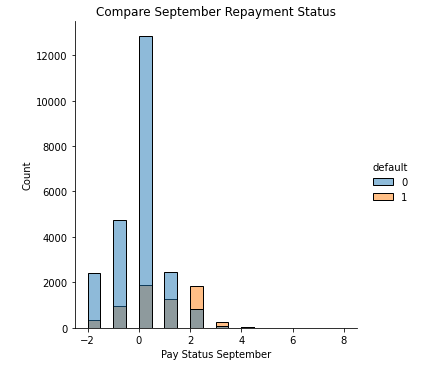
Exploratory Data Analysis
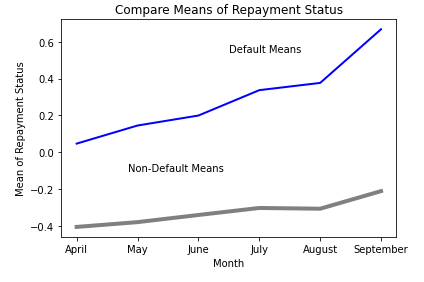
The EDA shows there are distinctions between the default records and the non-default records.
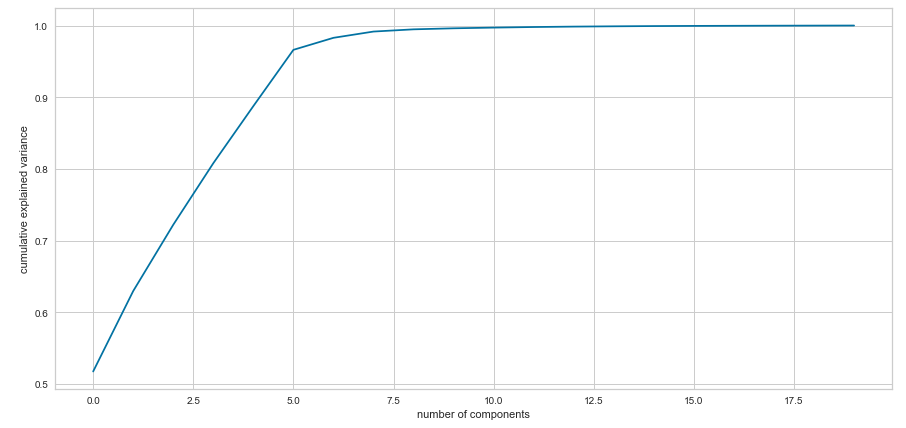
Principal Component Analysis
PCA was implemented because of multicollinearity between groups of input variables.
Modeling
The imbalanced target variable was addressed by using predicted probabilities for positive outcome based on best classification threshold, and for the Artificial Neural Network, by weighting the binary target classes.
Evaluation
Gradient Boosting Classification, Logistic Regression and Random Forest Models:
Artificial Neural Networks: