Insurance Fraud in Python
Classification Prediction
Summary
The goal of this project was to use Python to identify significant features in fraudulent insurance claim transactions and to design predictive classification models to predict whether fraud was reported on the insurance claim transaction. The project addressed the imbalanced target variable by weighting the classes. Logistic Regression, Support Vector Machine Classification, and Random Forest models were tested. The paper walks through the data understanding and preparation, different models tested, methodology, and evaluation of the project.
Tools
- Scikit-learn
- Seaborn
- Matplotlib
- Yellowbrick
- Numpy
- Pandas
- Scipy
- Patsy
- Tabulate
- Counter
Data: claims
Methodology
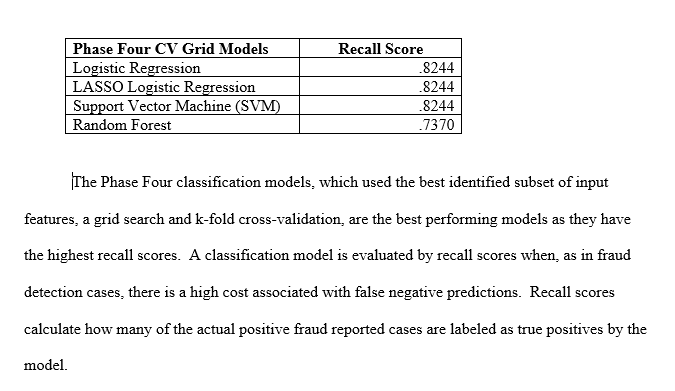
Compared multiple versions of models that varied techniques for data-splitting, the imbalanced target variable, and feature selection.
Models / Methods / Metrics
- Random Forest
- Logistic Regression / LASSO Logistic Regression
- Support Vector Classification
- Principal Component Analysis
- Log-Transformation and Scaling
- GridSearch
- Recall
Project Preview
Exploratory Data Analysis
This project utilized the EDA from this Exploratory Data Analysis and Hypothesis Testing project: EDA.
Principal Component Analysis
PCA was implemented because of multicollinearity between groups of input variables.
Evaluation