Insurance Fraud in R
EDA and Classification Prediction
Summary
This was my first data science project. The focus of the course was statistical analysis using R. The goal of this project was to use R and statistical analysis to identify significant features in fraudulent insurance claim transactions and to design a classification model to predict whether fraud was reported on the insurance claim transaction. K-Nearest Neighbor was the model tested. The paper walks through the steps to the project.
Libraries
| ggplot2 | tidyr | pastecs | ggm | psych | plyr | VIM | caTools |
| QuantPsyc | dplyr | foreign | car | class | caret | ltm |
Data
Models / Methods / Metrics
- K-Nearest Neighbor
- Correlation and Partial Correlation
- Multicollinearity: Logistic Regression and vif() function
- Feature selection: Variable coefficients and odds ratio
Exploratory Data Analysis Preview
The EDA showed that there are distinctions between the fraudulent records and the non-fraudulent records.
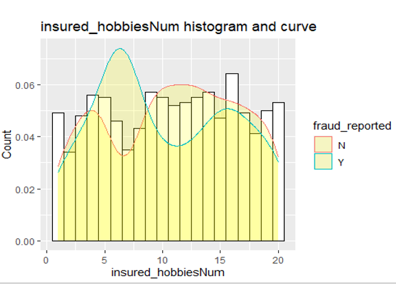
Hobbies
The claimant’s hobbies show some variation in fraud cases.
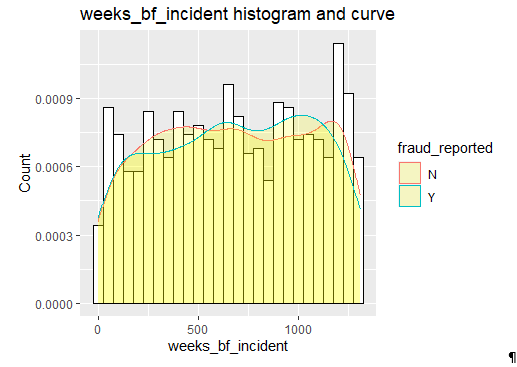
Weeks Before Incident
The number of weeks the policy was owned before the claim show some variation in fraud cases.