Fraud Prediction in R: Credit Card Transactions
Unsupervised Learning for Predicting Credit Card Fraud in R
Summary
The goal of this project was to use R to design unsupervised predictive binary classification models to predict whether credit card transactions are fraudulent transactions. One Class Support Vector Machine and k Means clustering models are highlighted. The paper and presentation walk through the data understanding and preparation, different models tested, methodology, evaluation and anticipated follow-up steps to the project.
R Libraries
| e1071 | NLP | tm | dbscan | fpc | MLmetrics | NBClust | factoextra | corrplot | dplyr | ggplot2 | caret |
Data
Models / Methods / Metrics
- One Class Support Vector Machine
- K Means Clustering
- Elbow Method
- DBSCAN Clustering
- Logistic Regression
- Support Vector Machine (Two Classes)
- Feature Selection:
- Near Zero Variance
- Learning Vector Quantification
- Recursive Feature Elimination
- Boruta
- LASSO Regression
- ovun.sample (Random Under-Sampling)
- Recall and F1
Results
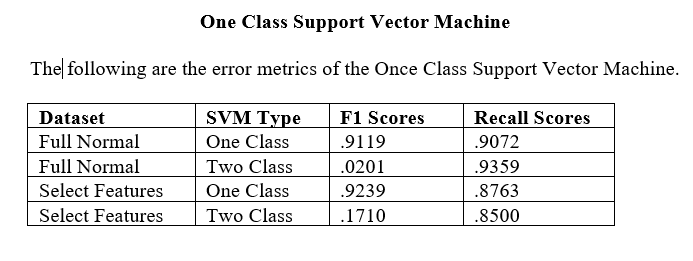
The unsupervised One Class SVM model is a viable model for predicting credit card frauds. Utilizing the k means clusters as features or labels in supervised models are also viable methods.
Project Preview
Exploratory Data Analysis
The EDA shows there are distinctions between the fraud records and the non-fraud records.
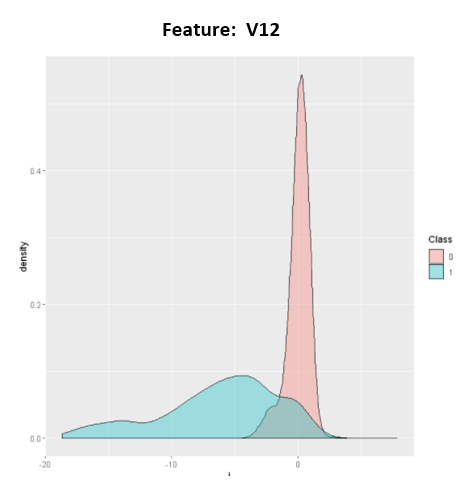
K Means Clusters
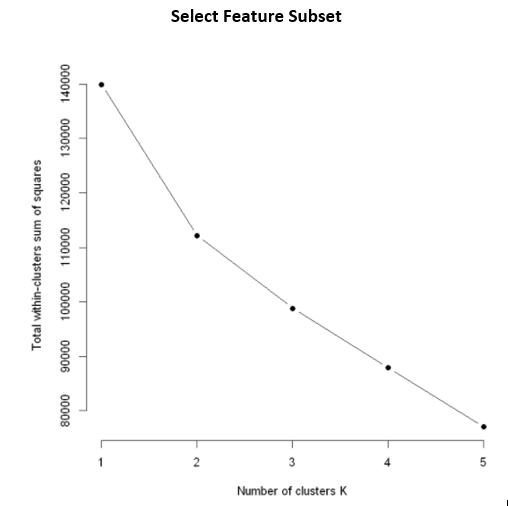
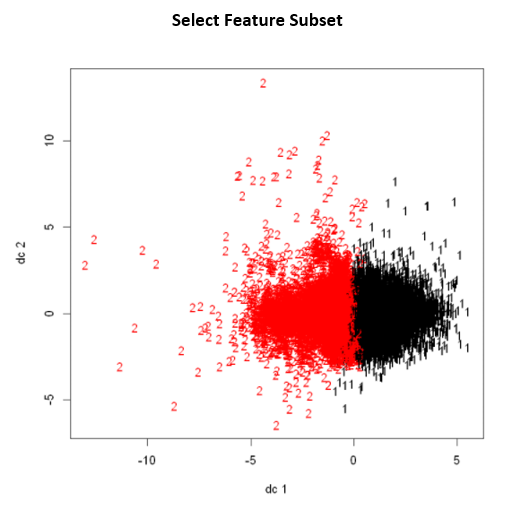
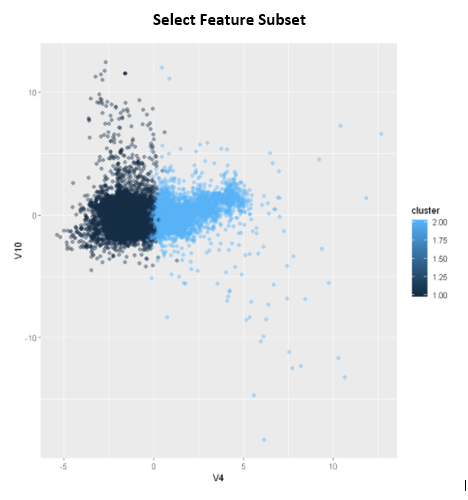
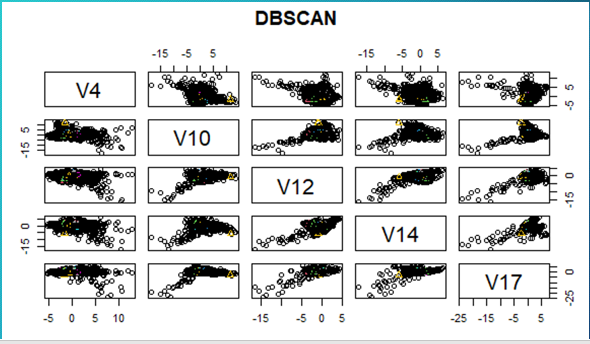

Modeling
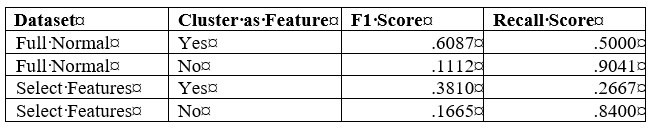
The unsupervised learning methods I analyzed were One Class Support Vector Machine, k means clustering and DBSCAN clustering. I compared the results of the unsupervised learning models with supervised classification models. I tested the k means models with the clusters as input features and as classification labels in supervised models. In each model, I used a dataset with all the input features except three non-normal features that I dropped. I also tested each model with only the 5 features identified as the most significant features.
In the unsupervised models, I used the original highly imbalanced proportion of fraud vs non-fraud cases. However, the imbalance must be addressed in the supervised models used for comparison. Therefore, I under-sampled the training data for the supervised models.
Evaluation
One Class Support Vector Machine:
K Means:
Clusters as input features in the supervised model:
Clusters as the classificaiton labels in the supervised model: